




Understanding how codecs work

One of the most abstract attributes of Voice over IP (VoIP) is the codec. We may wonder which codec to use in a given situation. Of course, there are general industry guidelines that help us make such decisions, but it can be unnerving to blindly follow recommendations without knowing why. For example, why should G.729 be preferred over the G.711 codec for WAN links? Why should I use G.722 when I don’t have an issue with bandwidth? What are the advantages of iLBC and Opus over the G series of codecs and when should I use them?
In a future article, we’ll be looking at the various codecs that are available for voice. First, though, let’s understand how the human voice is digitized. This will then allow us to more readily grasp the advantages and disadvantages of each codec.
What is a codec?
The word codec is a portmanteau or a linguistic blend of the term “coder-decoder.” A codec is a method or an algorithm by which signals are encoded and subsequently decoded. When applied to VoIP, a codec is a method by which the sound of the human voice, is digitized into ones and zeros so that it can be sent over a network. Once the digitized voice arrives at its destination, it is then decoded or converted back into sound that can be heard by the human ear and understood. The resulting sound is always an approximation of the original, and its quality depends on the codec being used.
Codecs are by no means exclusively used for VoIP. The music and video industry makes extensive use of codecs to record, store, and transmit media. The use of codecs for VoIP is a specialization within this broader field of expertise.
Analog versus digital
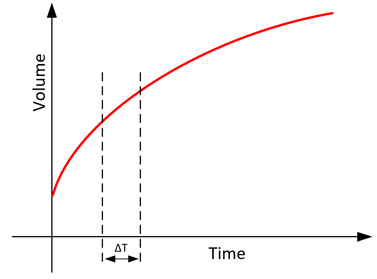
We live in an analog world. Everything from sound, to color, to smells, and a host of other things are analog phenomena. What makes something analog is that it can have an infinite number of values inbetween two values. Using sound as an example, let’s take the attribute of volume. A sound can have a volume of 1 and a volume of 10 and an infinite number of values between those two levels. The following graph shows an example of the increasing volume of a sound over time. Notice that the line is smooth and, if you move forward ΔT in time, even if ΔT is infinitesimally small, the volume will increase an equally infinitesimal amount.
Conversely, when referring to a digital phenomenon, we are referring to something that does not have an infinite number of values between two values, but a discrete and finite number. Using the same example as above, a digital representation of the change in volume of a sound over time will look like this.
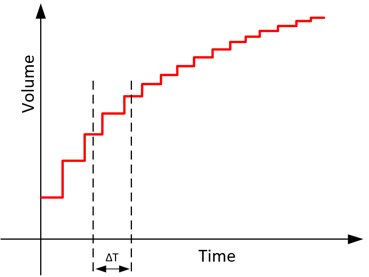
Notice that the curve is no longer smooth but has distinct values as time progresses without the possibility of having values in between those shown. Since there is only a fixed number of values possible, if ΔT becomes small enough, there will be no change in the volume over the time of ΔT.
A similar digital representation can be made of every other aspect of the human voice, such as pitch, tone, and timbre. The more “steps” there are in the digitized representation of the sound, the more accurately the original sound is represented and the higher the quality of its reproduction. The number of “steps” primarily depends on two factors: sampling rate and bit depth.
Sampling rate
Sampling rate refers to how often a sound is sampled or “listened to” and encoded. Each sample that is recorded is represented by a specific digital value. Below is an example of how sampling works. The red waveform is the sound and the blue dots indicate the samples. The X axis is time and the Y axis shows the values assigned to each sample from 0 to 15. Once you have a digital value for each sample, all that is needed to express it as ones and zeros is to convert it to binary format.
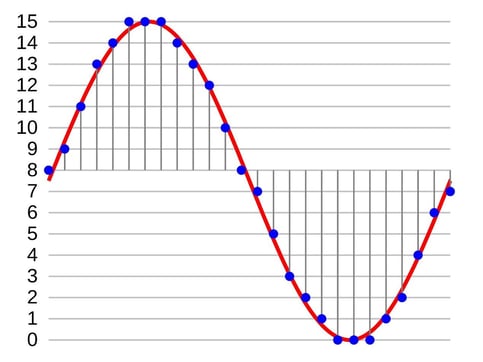
If you increase the sampling rate (in this case, the number of blue dots), you will encode more information, providing a more accurate representation and a higher sound quality when reproduced. Sampling rate is measured in Hertz, which is a unit of frequency. For example, a sampling rate of 1 kHz means that the sound is sampled 1000 times per second.
When digitizing sound, it has been found that you must use a sampling rate of twice the highest frequency of sound that you want to digitize in order to accurately reproduce the sound. This is called Nyquist’s theorem. The human speaking voice typically has frequencies of up to 4000 Hz, so a sampling rate of 8000 Hz is sufficient to sample it with an acceptable quality. This is why a sampling frequency of 8 kHz is often found within codecs used for VoIP.
If you have a high enough sampling rate, you can make the reproduced sound so accurate that the human ear will be unable to discern the difference between it and the original. CD quality music is an example of such digitization. The human ear can typically hear sounds with frequencies of up to 22 kHz. For this reason, CD quality music exceeds 44 kHz sampling rates, twice that of the highest audible frequency.
Bit depth
To understand bit depth, let’s take a closer look at the graph.
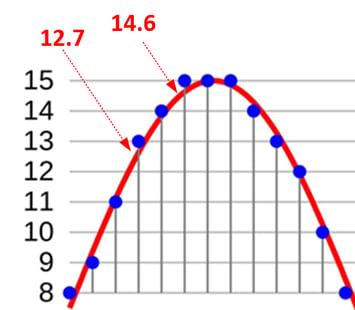
You will notice that the blue dots do not coincide exactly with the red waveform. Each sample can only have integer values of 0 to 15. In some areas of the graph, the dots should be placed at 12.7 or 14.6. But, since this is not possible, the dots are placed at the nearest whole number.
In order to increase the accuracy of each sample, instead of having only 16 available values to represent it, you can have 32 or 64 or 128 or more. The higher the number of values per sample, the more accurate the representation of the sound. This attribute is referred to as bit depth. The following series of graphs illustrate how a higher bit depth can produce a more accurate digital representation.
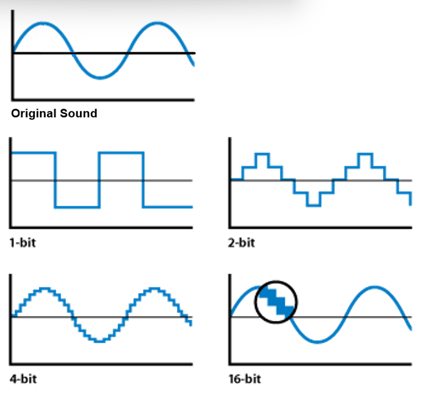
A 4-bit bit depth will provide 24=16 values for each sample while a 16-bit bit depth will provide 216=65536 values per sample, vastly increasing the accuracy of approximation of each individual sample.
Compression
Strictly speaking, the higher the sampling rate and the higher the bit depth, the higher the quality of the representation of the sound and thus its subsequent reproduction. But there is a tradeoff. The higher the quality, the higher the required bandwidth. In order to save bandwidth, codecs will use various compression algorithms to maintain a higher level of quality while decreasing the actual size of the digitized voice, and thus facilitating its streaming. While compression does decrease the sound quality somewhat, it can achieve a better quality to size ratio, increasing the efficiency of voice transmission.
Bringing it all together
For VoIP, codecs are all about delivering the best voice quality for the amount of bandwidth that is available. If bandwidth was not an issue, we could provide CD quality voice over all networks and be done with it. But because this is not the case, codecs are necessary.
Each codec will supply mechanisms for a specified sampling rate, bit depth, and compression. Each combination will result in a specific required bandwidth. For example, the G.711 codec provides a sampling rate of 8000 Hz, using Nyquist’s theorem, and a bit depth of 8 bits, resulting in a required bandwidth of 8000 Hz*8bits = 64kbps. Because the original version of this codec does not use compression, the required bandwidth remains unchanged.
Other codecs will employ various combinations of sampling rates, bit depths, and compression mechanisms to achieve their results. Depending on the needs of the network and the equipment being used, the appropriate codec can be chosen.
Additional attributes
In this article, we have covered the basic attributes that define codecs. However, codecs can deliver other functionalities such as dealing with packet loss and jitter, minimizing latency, reducing CPU load for encoding and decoding, as well as providing predictive algorithms that will proactively improve voice quality in the case of adverse network problems. These are also important properties that must be taken into account when choosing a codec and will be addressed in a future article.
Conclusion
Understanding how the human voice is digitized and how the various codecs combine sampling rates, bit depth and compression to achieve a specific voice quality/size ratio will help you make the best decision about which codecs to employ on a given network.
In a future article, we will showcase some of the most commonly used codecs in the industry, along with their additional features and mechanisms.
You may also like:
Quality of service must-haves for converged networks
QoS for VoIP networks: IntServ vs. DiffServ
Using Wireshark to troubleshoot VoIP




Comments